联系:QQ(5163721)
标题:CPU E5 / E5 v2 / E7 v2的运行超过208天后,热重启后系统异常
作者:Lunar©版权所有[文章允许转载,但必须以链接方式注明源地址,否则追究法律责任.]
昨天朋友(感谢bbq和很多热心朋友)告知一个Linux的bug:
E5 / E5 v2 / E7 v2的运行超过208天后,热重启后(比如 shutdown -r),TSC时钟不能被clearout,因此在重启后TSC会继续之前的计数,造成系统异常。
(涉及的Linux内核版本列举在最下面红帽说明中)
.
红帽的官方说明:
https://access.redhat.com/solutions/433883
.
由于Linux时钟机制引起的bug很多,
Linux中有3种timer:
1、Real Time Clock(RTC):RTC是位于CMOS中的
2、Programmalbe Interval Timer(PIT):PIT主要由8254时钟芯片实现的
3、Time Stamp Counter.(TSC):TSC的主体是位于CPU里面的一个64位的TSC寄存器。每个CPU时钟周期其值加一
类似的时间引起宕机的问题很多跟Linux的TSC时钟机制有关系,比如:
.
今天看见飞总也在讨论, 具体参见:
http://www.xifenfei.com/5760.html
.
Exadata X5目前没有发现这个问题:
Exadata的db node: CPU E5 2699 v3; cell node: CPU E5 2630 v3; db node和cell node都采用OEL 6.6
.
针对这个Linux 在E5 V2和E7 v2(RHEL 6.1~6.4)的bug,我补充一下Oracle对此的官方说明:
SYMPTOMS
Oracle Linux server bootup hangs upon the clock initialization stage after warm-reboot of the system. This issue could occur under the following conditions:
The system contains Intel Xeon E5 / E5v2 / E7v2 family processors, affected by Intel Errata BT81.
Approximately 208.5 days or more passed after the previous power-cycle.
Running either Oracle Linux 5.x with UEK, Oracle Linux 6.4 or earlier.
x86_64 system
Followings have no impact:
Any 32-bit system
Oracle Linux 5.x running Red Hat Kernel (2.6.18-x)
Oracle Linux 7.x
.
.
CHANGES
The operating system (OS) was recently rebooted without power-cycling.
.
.
CAUSE
The root cause of this issue the combination of these two below:
Intel Xeon processor E5 / E5 v2 / E7 v2 has the issue where TSC is not cleared upon receipt of reset signal. This makes TSC continues counting up when the operating system issued the warm-reboot.
x86 kernel booting code contains the clock initialization. In there, when set_cyc2ns_scale() is called, improper handling of possible overflow due to unexpectedly large value from TSC. This is similar to the overflow issue in cyc2ns_offset(), where returning value could overflow if TSC value is too large, which could occur approximately 208.5 days after power-cycle.
The cause is the same as the issue reported in the following documents, however, the previous fix did not cover all the potential overflows.
Linux OS reboots every 208 days (Doc ID 1482279.1)
System Crash After 208 Days Of Continuous Uptime (Doc ID 1496633.1)
SOLUTION
In a long term, please consider updating to the following versions of kernel:
For Oracle Linux 5.6, 5.7, and 5.8 with Unbreakable Enterprise Kernel (UEK),
Updating to the latest version of Unbreakable Enterprise Kernel Release 2 (UEK2) is the best solution. UEK2 version 2.6.39-300.0.4 or later covers the fix.
For Exadata 11.2.3.2.x with Oracle Linux 5.8, update to 11.2.3.2.2 which contains UEK1 backport fix as 2.6.32-400.34.1. Refer to Doc 1613511.1.
For Oracle Linux 6.0 – 6.4 with Unbrealable Enterprise Kernel Release 1 or 2 (UEK1/UEK2), update to the latest version of UEK2. In UEK2, version 2.6.39-300.0.4 or later contains the fix. Also consider updating to Unbreakable Enterprise Kernel Release 3 (UEK3), which is not affected by this issue.
For Oracle Linux 6.0 – 6.4 with Red Hat Compatible Kernel, update to kernel 2.6.32-358.23.2.el6 or later. Another option is to update Oracle Linux 6.5 (equivalent to 2.6.32-431.el6) or later.
For Oracle Linux customer with Long Term Support Contract, please consult with Oracle Linux Support.
同时,针对这个bug,Oracle给出了一个internal的workround:
For a short-term solution, power-cycling the system will resolve the issue, because this will forcibly reset TSC.
demo代码:
Example code for 2.6.32-358.23.2.el6 (arch/x86/kernel/tsc.c)
static void set_cyc2ns_scale(unsigned long cpu_khz, int cpu)
{
unsigned long long tsc_now, ns_now, *offset;
unsigned long flags, *scale;
local_irq_save(flags);
sched_clock_idle_sleep_event();
scale = &per_cpu(cyc2ns, cpu);
offset = &per_cpu(cyc2ns_offset, cpu);
rdtscll(tsc_now);
ns_now = __cycles_2_ns(tsc_now);
if (cpu_khz) {
*scale = ((NSEC_PER_MSEC << CYC2NS_SCALE_FACTOR) +
cpu_khz / 2) / cpu_khz;
*offset = ns_now - mult_frac(tsc_now, *scale, <<<<<<<<<
(1UL << CYC2NS_SCALE_FACTOR)); <<<<<<
}
sched_clock_idle_wakeup_event(0);
local_irq_restore(flags);
}
红帽的官方说明:
https://access.redhat.com/solutions/433883
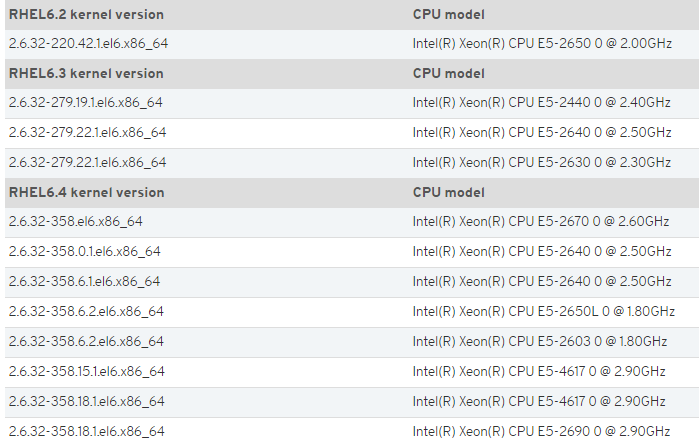
下面摘出来受影响的kernal列表:
Environment
Red Hat Enterprise Linux 6.1 (kernel-2.6.32-131.26.1.el6 and newer)
Red Hat Enterprise Linux 6.2 (kernel-2.6.32-220.4.2.el6 and newer)
Red Hat Enterprise Linux 6.3 (kernel-2.6.32-279 series)
Red Hat Enterprise Linux 6.4 (kernel-2.6.32-358 series)
Any Intel® Xeon® E5, Intel® Xeon® E5 v2, or Intel® Xeon® E7 v2 series processor
The issue has been observed in the following environments with 64-bit kernels. Notice that 32-bit kernels of the above mentioned versions are prone to the issue too.
.