
联系:QQ(5163721)
标题:Exadata的数据保护机制(冗余机制)- 3-Failure Group
作者:Lunar©版权所有[文章允许转载,但必须以链接方式注明源地址,否则追究法律责任.]
为了补充前面两篇的一些概念,这里,我们简单介绍下ASM的Failgroup。
ASM提供了3种冗余方法。
EXTERNAL,即ASM本身不做镜像,而依赖于底层存储阵列资深实现镜像;在External下任何的写错误都会导致Disk Group被强制dismount。在此模式下所有的ASM DISK必须都完好,否则Disk Group将无法MOUNT。
.
NORMAL, 即ASM将为每一个asmfile extent创建一个额外的拷贝以便实现冗余;默认情况下所有的asmfile都会被镜像,这样每一个asmfile extent都有2份拷贝。若写错误发生在2个Disk上且这2个Disk是partners时将导致disk Disk Group被强制dismount。若发生失败的磁盘不是partners则不会引起数据丢失和不可用。
.
HIGH, 即ASM为每一个asmfile extent创建两个额外的拷贝以便实现更高的冗余。2个互为partners的Disk的失败不会引起数据丢失,当然,不能有更多的partners Disk失败了。
数据镜像依赖于failure group和extent partnering实现。
.
ASM在NORMAL 或 HIGH 冗余度下可以容许丢失一个failure group中所有的磁盘。
.
下面我来详细说下,Oracle如何通过failure group来提供数据的高可用性。
首先,ASM使用的镜像算法并不是镜像整个disk,而是作extent级的镜像。ASM会自动优化文件分布以降低设备故障造成数据丢失的可能性。
在normal redundancy模式下,ASM的按照extent进行striping时是在一个DiskGroup中完成的(即,在一个DG的2个Fail group之间完成的,而不是一个单独的FG中完成),ASM环境中每分配一个extent都会有一个primary copy和一个secondary copy,ASM的算法保证了secondary copy和primary copy一定是在不同的failure group中,这就是failure group的意义。

这里我们看到:这里有一个Normal Redundancy的磁盘组,他有2个Failure Group(FG1和FG2),每一个Failure Group中包含了2块磁盘(FG1中包含了Disk0和Disk1,FG2中包含了Disk2和Disk3)
可以看到,ASM分配extents时(asmfile的extent,对应到磁盘上就是AU),extent的分配并不是杂乱无章的,非常有规律的(有一个算法)。
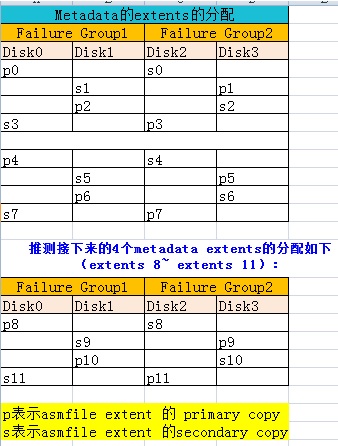
上述推测可以在data extents的分配中得到验证。当然,实际情况可能是,每个Failure Group存在很多盘,但是分配的算法还是类似这样的。
.
在10g ASM中,默认情况下读取数据时,数据库实例(RDBMS)总是去读取主primary extent,ASM实例不让RDBMS去读备用的镜像拷贝extent(除非是primary copy不可用,才能读取secondary copy),即使这样IO还是均衡的。当数据库实例(RDBMS)将数据写入文件的时候,primary copy可能在任何一个failure group中,而secondary copy则在另外的failure group中。
.
11.1的ASM引入了Fast mirror resync特性,该特性主要为extended distance RAC设计,不建议在常规ASM中使用。
.
Fast mirror resync特性主要是根据11.1引入的PREFERRED_READ_FAILURE_GROUP参数来设置让本地节点优先读取某个failure group中的extent。
.
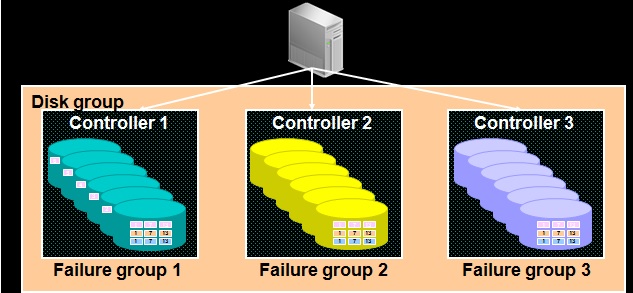
Failure Group的构成是与设备相关的。用户要根据系统中各组件的容错要求来设定Failure Group。
例如,系统中有五块磁盘及一个 SCSI 控制器(SCSI controller)。如果 SCSI 控制器发生故障将导致所有磁盘失效。在此种情况下,用户应将每个磁盘放入不同的Failure Group(在不同的SCSI 控制器下)。
例如这里,我们有3个SCSI 控制器(SCSI controller),每个控制器上连接了6块磁盘,好的设计是针对每一个SCSI 控制器(SCSI controller)下面盘分别创建Failure Group,这样才能真正利用Failure Group的概念来容错。
.
在Exadata上,每个cell都是一个failure group……





